

在口试的过程当中,偶尔会遭逢一些场景题,天然这些场景题九九归一依然技能问题,但他频繁比旧例的八股题要稍稍难一些,因为他教师的是你关于技能的合座意会、愚弄,以及变通的材干。
那么今天我们就来看一说念,在口试中国祥瑞时遭逢的一说念场景题:将百万数据插入到 Redis,有哪些已矣决策?
1.Redis 上风与挑战
最初,Redis 看成一个开源的内存数据结构存储系统,支撑多种数据结构,如字符串、哈希表、列表、围聚和有序围聚等,它具有以下显赫上风:
高速读写:Redis 将数据存储在内存中,好像已矣极快的读写操作,至极相宜对性能条件高的场景。
丰富的数据结构:不错凭证不同的业务需求选定合适的数据结构来存储数据。
支撑捏久化:不错将数据捏久化到硬盘,保证数据的安全性。
然则,当需要插入百万数据时,也面对着一些挑战:
内存压力:大批数据可能会占用大批内存,需要合理筹谋内存使用。
性能瓶颈:若是插入操作欠妥,可能会导致性能着落,致使影响系统的频频运行。
那若何来贬责这些问题呢?接下来我们一说念来看。
2.已矣决策概括
百万数据插入 Redis 的合座实行经过如下:
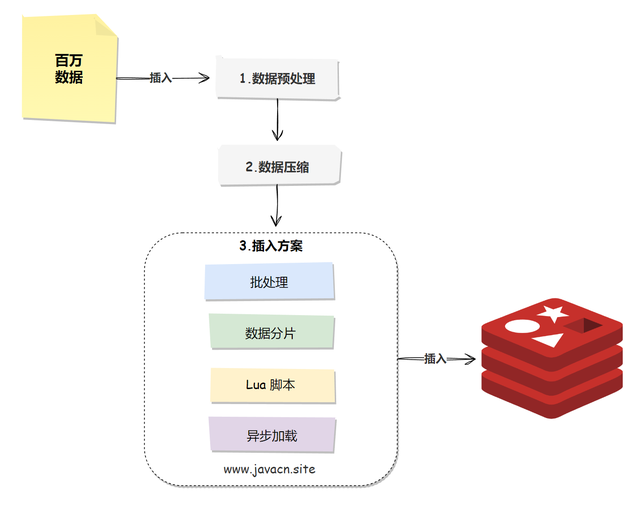
3.前置职责:预处理和压缩
在启动实行数据插入之前,不错先进行以下操作:
数据预处理:在写入之前对数据进行必要的预处理,比如去除重叠数据、调理数据时局等,不错减少骨子写入 Redis 的数据量,栽培效果。
数据压缩:若是存储的数据不错进行压缩的情况下,不错商量使用 Redis 的压缩功能(如 LZF、Snappy 等压缩算法)来减少内存占用。压缩后的数据占用更少的内存,不错栽培存储容量和存取速率。
4.插入决策
百万级数据插入 Redis 不错吸收的决策有以下几个:
批处理
数据分片
使用 Lua 剧本
异步加载
接下来,我们离别看来。
4.1 批处理
Redis 批处理的技能有以下两个:
使用管说念技能(Pipeline):允许客户端发送多个号召到处事器,而不需要恭候每个号召的恢复。这减少了收罗延伸的影响,栽培了写入速率。
使用批量操作领导:如使用 MSET 或 HMSET 号召不错一次斥地多个键值对或哈希表字段,这比单独使用 SET 或 HSET 要快得多。
4.2 数据分片
数据分片指的是使用 Redis 的分片功能,将数据分散在多个 Redis 实例或节点上,不错商量使用 Redis 集群。集群模式下,数据不错分散在多个节点上,从而分散负载并栽培写入糊涂量。
4.3 使用 Lua 剧本
也不错通过 Lua 剧本将多个操作组合成一个原子操作,减少客户端与处事器之间的通讯次数。
4.4 异步加载
将一个大任务分红多个小任务,然后再通过异步加载的面容批量写入 Redis,这么不错幸免阻难干线程,栽培愚弄的合座反应性。
取得更多企业口试真题,加 V:VipStone【备注:祥瑞】。
5.优化残酷
除了以上技能除外,我们还不错通过以下技能优化 Redis:
诊疗 Redis 设置参数:凭证骨子情况诊疗 Redis 的内存收敛、捏久化计谋等参数,以栽培性能和牢固性。
监控内存使用情况:使用 Redis 的监控器具,及时监控内存使用情况,幸免内存溢出。
小结
将百万数据插入到 Redis 是一个具有挑战性的任务,但通过合理选定已矣决策和进行性能优化,不错高效地完成任务。以上已矣症结皆有各自的优舛误,斥地者不错凭证骨子情况选定最相宜的决策。同期,把稳诊疗 Redis 的设置参数和监控内存使用情况,以确保系统的牢固运行。
本文已收录到我的口试小站 [www.javacn.site](https://www.javacn.site),其中包含的内容有:Redis、JVM、并发、并发、MySQL、Spring、Spring MVC、Spring Boot、Spring Cloud、MyBatis、盘算模式、音尘部队等模块。